1.集合的体系
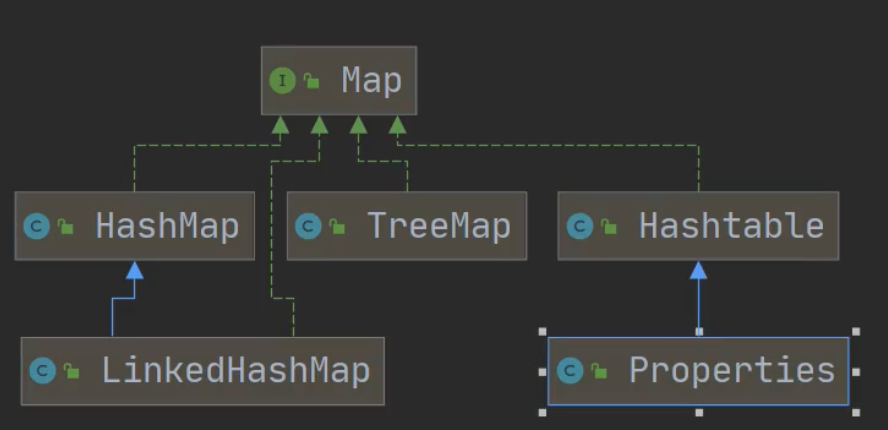
Java集合总的分为两种:单列集合(Collection)和双列集合(Map),继承关系如下:
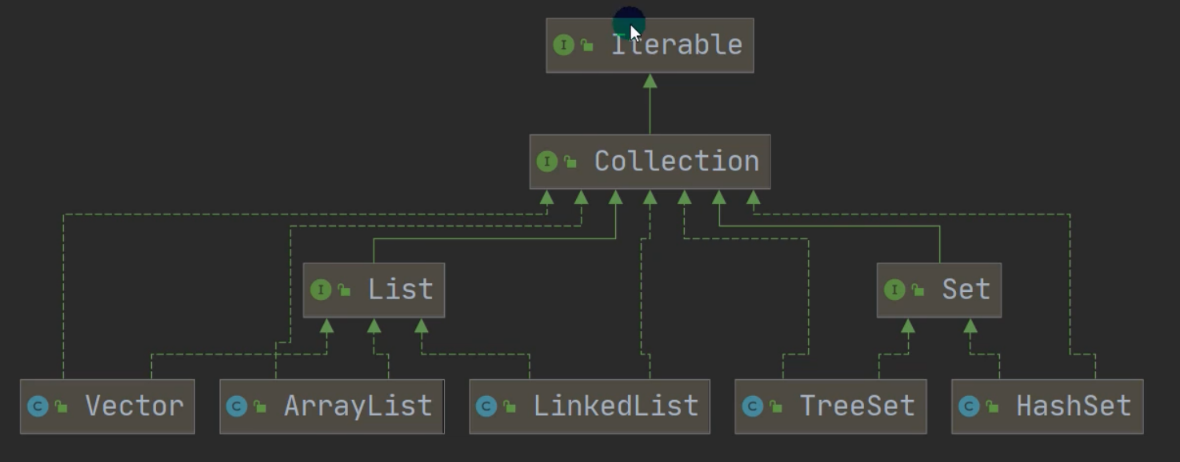
2.Collection接口
1. List接口:
1.1 ArrayList类
ArrayList维护了一个Object类型的数组:Object[] elementData
创建对象时如果使用的无参构造,则数组初始容量为0,加第一个元素后容量变为10。
为方便描述和区分扩容和临界,接下来【数组的容量】指数组的整体长度,【数组的长度】指数组中已经被存放元素的个数(不包含数组初始化时赋值的null)
如果使用指定大小(int)的有参构造,则数组初始化为指定大小;如果有参构造的参数是一个集合,会初始化成一个该传入集合的复制数组。
扩容机制为原来容量的1.5倍,在数组长度到达容量时(也就是容量的1.0倍)会促发扩容机制,称1.0为加载因子
比如无参构造创建后的数组容量为10,长度到达10后,容量扩容为15
ArrayList在遍历过程中进行add或remove会发生什么?
这要看你用的是哪种遍历方式:fori 还是 foreach?
如果是for i ,在删除多个元素的时候可能会漏删或错删,因为fori是用下标来删的,删了后面的元素就会前移,不建议用这种方式。
如果是foreach,我们知道,foreach其实是语法糖,本质上还是用的迭代器遍历。但在遍历进行remove操作的时候,要注意是调用迭代器的remove方法,而不是arraylist对象的remove方法。
原因是在ArrayList类中,存在一个remove方法,但是该类还有一个实现了Iterator接口的Itr内部类,Itr类也有一个remove方法。两者的区别是:
在ArrayList中有个modCount的值,初始为0,表示对集合的修改次数
在迭代器中存在一个叫expectedModCount的计数变量,它表示对ArrayList修改次数的期望值,它的初始值为modCount,也就是0
在迭代器进行next方法时,会先进入checkForComodification函数,判断expectedModCount和modCount是否相等,如果不相等会抛出该异常。如果是调用的arraylist的remoive方法,modCount++,expectedModCount并不会自增,导致但是迭代器在下一次next方法中发现两个变量不符,所以就会报异常。
但实际上迭代器中的remove方法中还是调用的arraylist的remove方法,逻辑和ArrayList中的一样,但是会进行expectedModCount = modCount;的复制操作,所以如果在单线程的遍历过程中需要移除元素的话,要使用迭代器遍历,并用迭代器的remove方法。
但在多线程的遍历remove中ArrayList就不适用了,那么vector是否可以呢?
实际上vector也会抛异常,尽管有synchronized修饰加锁,但迭代器是没有加锁的,而且每个线程都会创建一个私有的迭代器,导致expectedModCount也是独立私有的,而modcount是共享的,也是会出现不一致的问题。
所以最好的解决方法是使用CopyOnWriteArrayList
1.2 Vector类
Vector也是维护了一个Object类型的数组:Object[] elementData,和ArrayList类似。但相较于ArrayList,Vector效率不高,但Vector的方法都有synchronized修饰,Vector的操作是线程安全的。
Vector的无参构造直接就将数组初始化为10。
扩容机制为原来容量的2倍,加载因子为1.0。
tips:Vector的操作方法虽然有Synchronized修饰,但只能说是相对线程安全的。
只能避免多个线程同时操作一个方法,多个线程操作多个方法的时候还是会出问题,这时就需要使用同步代码块解决了
1.3 LinkedList类
LinkedList实现了List接口和Deque接口,底层是一个双向的Node链表,因此可以在任意位置插入或删除元素。
小总结:
由于ArrayList底层是一个数组,所以在查找方面的时间复杂度是O(1),而增删方面是O(N);
而LinkedList底层是双向链表,反而增删很容易,查询比较难
所以如果我们改查操作多,可以使用ArrayList或Vector;增删操作多选择LinkedList
| 底层结构 | 增删效率 | 改查效率 | 线程安全性 | |
|---|---|---|---|---|
| ArrayList | 可扩容的数组 | 较低,通过数组扩容 | 较高 | 不安全 |
| LinkedList | 双向链表 | 较高,通过链表节点的追加或插入 | 较低 | 不安全 |
| Vector | 可扩容的数组 | 较低,通过数组扩容 | 低于ArrayList | 安全 |
2.Set接口
2.1 HashSet类
(不可重复,在比较对象时需要重写equals方法)
HashSet是通过一个HashMap实现的,而HashMap的本质是个【数组 + 链表 / 红黑树】,所以存放元素时是无序的。
Ⅰ.对HashMap的结构理解如下:
HashMap的本质是一个数组,这个数组的类型是单向键值对Node,即:Node<K,V>[ ] table
Node是一个有着next指针的节点,因此table数组的元素是一个Node链表
table索引的选择是通过一个哈希函数 hash(key)实现的:
hash:
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);index:
tab[i = (n - 1) & hash];将key的hash与数组长度n相与,得到的结果总是会在n内,使得下标不会越界
Ⅱ.元素添加机制:
- 根据元素(key)哈希值定位到Node数组的索引,查看该位置的Node是否为空?
- 为空直接赋值,不为空需要判断数组元素的类型:
- 如果Node类型是TreeNode(红黑树),就按树的方式遍历,否则就说明已经是条链表,循环使用equals()方法遍历(这个方法需要重写,按照自己的比较需求设计。毕竟元素可以是String也可以是Object),相等则放弃,不相等则在链尾插入
Ⅲ.扩容机制:
数组初始容量是16,当成功添加的Node数到达容量的0.75倍(加载因子)也就是 12 后,就会扩容成2倍(32);
注意是成功添加的Node数,不管这12个Node是在同一条链表上,还是分散在数组的不同下标,只要添加到了12个,数组就会扩容。
而数组的元素:当【链表】的长度 ≥7 后继续在链尾添加Node会开启判断:如果此时数组长度 ≥ 64,会将这条链表转化为红黑树;如果数组容量不足64,则扩容数组,重新分配所有元素链表的数组索引。
注意:当某条链表长度已经≥7了后,在这条链表上加入第8个Node后数组容量要是小于64,数组容量就会直接扩容一倍变32,加入第9个就会从32扩容到64,这种情况是不会考虑加载因子的。
所以可以总结为:当某条链表长度到达8时,数组就会扩容。如果数组容量到达了64,链表就会变为红黑树。链表要转为红黑树的前提是数组容量必须到达64。
Ⅳ.HashSet与HashMap的关系:
毕竟是靠HashMap实现的,所以元素是以键:值的形式添加,k为要添加的元素,v为一个空Object【PRESENT】
【PRESENT】在HashMap是被static final修饰的,所以只有一份内存,每个v都是指向这个空对象
2.2 LinkedHashSet类
LinkedHashSet是HashSet的子类,底层是个LinkedHashMap,本质是个双向链表的数组。
数组的每个元素都是一条双向链表,但这个双向链表有区别与我们常见的双向链表,因为这种链表的每一个节点上有三个指针:Next、Before、After
实际上这种节点称为Entry,LinkedHashMap.Entry<k,y>是继承自HashMap.Node<k,y>的,为了添加两个新指针,创建了一个子类:Entry类来封装Node类。这两个新指针是用来保证添加数据的有序性的。
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
(假设接下来要添加的节点不重复,因此过程中会忽略掉节点的等值检验,实际业务中还是需要根据业务要求重写hashCode和equals方法的)
Next指针和HashSet中一样,用于指向该链表的下一个节点。使用到Next指针的是因为该添加节点的元素哈希值定位到了某个数组索引,遍历该索引里的链表,然后插入链尾。
可如果要添加的下一个节点在数组的另一个下标,但又为了实现LinkedHashSet能够记住元素添加的顺序,就需要用到Before和After指针:
- 首先这个新节点1在对应索引下的链表的链尾插入
- 然后让上一个添加节点0的After指向新节点1,新节点1的Before指向先前节点0
那么在加入新节点1的时候是怎么找到先前节点0的呢?
其实在LinkedHashMap中额外存在两个Entry节点:head和tail,
- head用于记录这个LinkedHashSet的入口节点
- tail记录着这个LinkedHashSet的最后添加的Entry节点。
因此每次要找到上一个节点的话,直接从tail拿就可以了。遍历LinkedHashSet的话也会从head开始访问。
对除next之外每个节点增加before和after两个指针,这两个指针用于实现元素存放的顺序,next用于实现链表的节点连接
2.3 TreeSet类
TreeSet是靠TreeMap实现的,区别在于TreeSet的key是加入的值,而value是指向一个空对象PRESENRT,具体了解看TreeMap,这里不多赘述。
小总结:
HashSet和LinkedHashSet都是基于HashMap实现的,存放的元素都是不重复的。
差别在于底层分别是一个单向链表数组和双向链表数组,而且HashSet的元素无序,LinkedHashSet的元素有序
| 底层结构 | 分布性 | |
|---|---|---|
| HashSet | 单向链表数组 | 无序 |
| LinkedHashSet | 双向链表数组 | 有序 |
| TreeSet |
3.Map接口
1.HashMap类
HashMap的底层和扩容实际上已经在HashSet中讲得差不多了,但需要补充的是HashMap中存在着一个叫【EntrySet<Map.Entry<K,V>>】的内部类,这个内部类值得好好讲讲。
重点:设计EntrySet这个类的目的就是为了方便遍历散列表,遍历的例子如下:
HashMap<String,Integer> map = new HashMap();
for (Map.Entry entry : map.entrySet()) {
Object key = entry.getKey();
Object value = entry.getValue();
}
首先这个内部类EntrySet存储的元素是Map.Entry<K,V>,可以通过调用HashMap的entrySet()方法获得,实例名叫entrySet。
public Set<Map.Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> es;
return (es = entrySet) == null ? (entrySet = new EntrySet()) : es;
}
而这个Map.Entry是Map接口的一个内部接口,但在HashMap中可以理解为Node,HashMap会将Map.Entry向下转换成Node。
为什么能转换?因为HashMap的底层【table】中存储的Node<K,V>就是实现的Map.Entry,因此每个Map.Entry指向的就是table中的Node。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
那已经存在了Node,为什么还要用Map.Entry来指向Node呢?
因为相较于Node,Map.Entry接口中这也就是为什么说 设计EntrySet这个类的目的就是为了方便遍历散列表。
除此之外,HashMap中还存在一个keySet()方法可以得到key的Set集合,一个values()可以得到vaule的Collection集合
2.Hashtable类
Hashtable和HashMap类似,本质也是个链表数组,但key和value不允许为null,线程安全
数组容量初始值为11,加载因子为0.75。扩容:2x+1,第一轮扩容:长度到达8,容量扩容到23
但Hashtable底层只是链表数组,链表不会树化,而且如果要添加新节点在链表上时,采用的是头插法
在HashMap中key可以为null,在hash函数中默认null的哈希值为0,value也可以为null
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
而在Hashtable中,key和value都是不能为null的,在put方法中发现value为null时会抛出空指针异常
3.TreeMap
TreeMap的底层是一颗红黑树,由一个个树节点【Entry】构成,Entry中包括了左右子树的指针和父节点指针,外加一个判断节点颜色的布尔值(BLACK:false,RED:true)。
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
}
由于红黑树是一颗自平衡的二叉查找树,插入的节点位置都在树的底部。因此TreeMap需要一个比较器【Comparator】来确定插入节点的位置来保持红黑树的平衡性。当我们使用HashTree的无参构造时,会默认生成一个按插入节点的key的字典序排序的比较器。
若插入节点发现该数为空,则新节点为根节点;若不为空,有以下步骤:
- 判断comparator是否为空,为空创建一个默认比较器,不为空则使用传入的自定义比较器。
- 按照比较器的规则遍历红黑树,直到遍历到叶子节点的父节点(红黑树的所有叶子节点都为null),确定新节点是父节点的左节点还是右节点。如果发现存在key相等的情况,会替换value,而key不会替换,然后return旧值value。
- 然后进入【fixAfterInsertion()】,根据插入的情况进行相关的染色、左旋和右旋等操作来保持红黑树的性质。
小总结:
| 底层结构 | 插入新节点方法 | 线程安全性 | |
|---|---|---|---|
| HashMap | 【数组】+【链表/红黑树] | 链表尾插法 | 不安全 |
| Hashtable | 【数组】+【链表】 | 链表头插法 | 安全 |
| TreeMap | 【红黑树】 | 二叉搜索树的遍历至底部插入 | 不安全 |

